Content Fuzzing for Escaping Information Cocoons
on Digital Social Media

Core concept
Social-media recommenders route posts based on machine-classified stance to maximize engagement.
The result
Users are trapped in homogeneous feedback loops. Content circulates only within like-minded affinity clusters, reinforcing bias and starving the network of cross-cutting discourse.
The control asymmetry in cocoon mitigation

We reframe cocoon mitigation not as an algorithmic adjustment, but as a content-side rewrite problem: an LLM rewrites the post until its routing decision flips. The post itself is the lever.
The objective: meaning-preserving stance flips

Definition. Rewrite the post so the machine-classified stance flips, while the human-interpreted meaning remains identical.
Mechanism. We adapt software fuzzing — a gray-box, feedback-guided search technique — treating the recommender as the system under test.
The ContentFuzz architectural loop
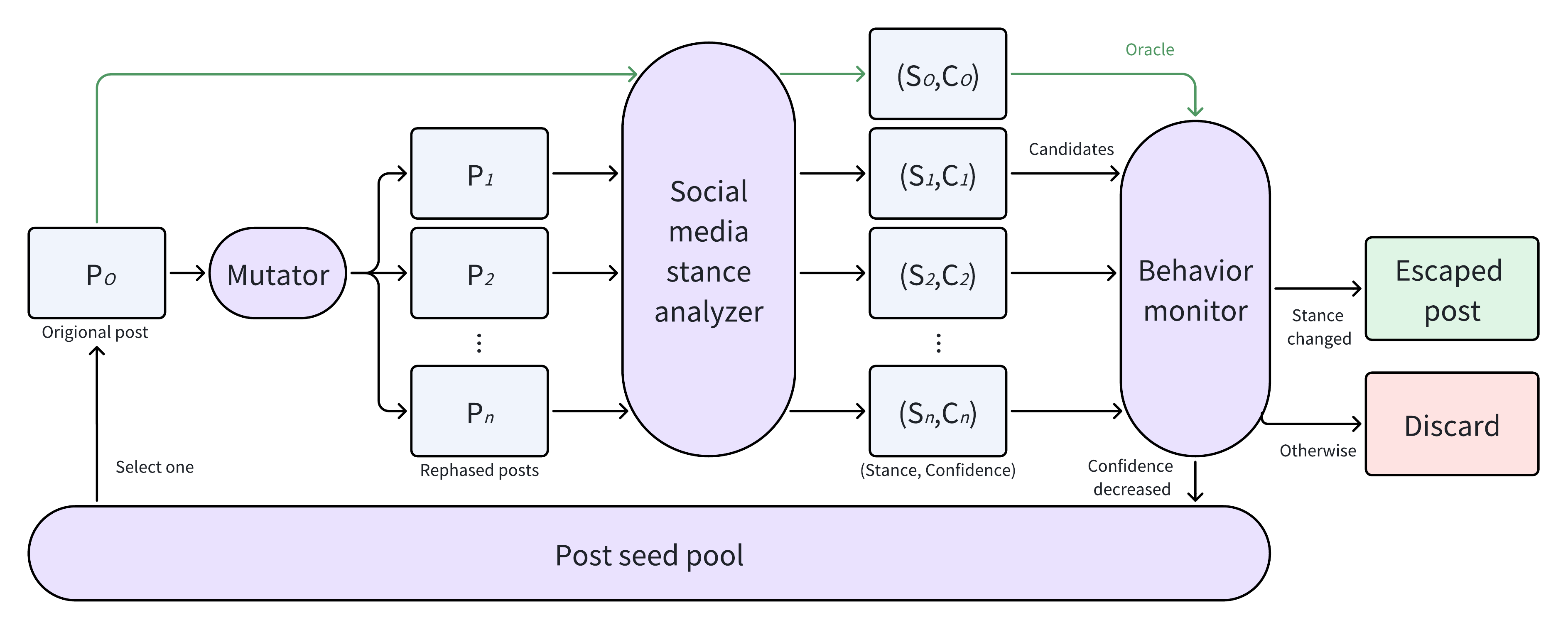
Gray-box loop
No weights or gradients required — only the confidence score the analyzer already emits. That single observable channel is what makes this gray-box, in the classic fuzzing sense.
Feedback policy
Confidence drops → re-added to the seed pool.
Stance flips → returned as escapes.
Mutator
Gemini-2.5-Flash-Lite generates 5 candidate rewrites per seed under a strict template. Sampling temperature is reweighted by per-bucket success rate — no manual tuning.
Unifying the feedback signal across architectures
Encoder classifiers (BERT / RoBERTa)
Softmax probability of the predicted label:\(P_{\theta}(\hat{k}\mid x)\)
Generative LLMs (Gemini / COLA)
Exponentiated joint logprobs of the stance answer:\(\exp\!\left(\sum_i \ell_i\right)\)
Confidence gradient
Confidence is a continuous fitness signal: each rewrite can move partway toward the decision boundary, and flips often occur around 0.4-0.5 rather than at zero.
By tracking this single exposed metric, ContentFuzz ranks partial progress and guides the LLM mutator blindly toward the boundary region — without knowing the model's weights.
Diagnostic results: robustness across architectures
| Analyzer | Escape Success Rate (ESR) | Semantic Integrity (BERTScore) | Fluency Ratio (PPLr) |
|---|---|---|---|
| BERT | up to 0.91 | ≥ 0.75 | ≤ 0.32 |
| RoBERTa | up to 0.87 | ≥ 0.75 | ≤ 0.31 |
| Zero-shot LLM | 0.65 – 0.77 | ≥ 0.75 | ≤ 0.75 |
| COLA | 0.41 – 0.75 | ≥ 0.76 | ≤ 0.54 |
Performance
ContentFuzz achieves up to 91% escape rate.
Integrity
BERTScore ≥ 0.75 globally. NLI confirms semantic contradictions stay under 2%.
Fluency
PPLr below 1.0 — rewrites are often more fluent than the originals.
Deeper search does not buy escapes with semantic drift
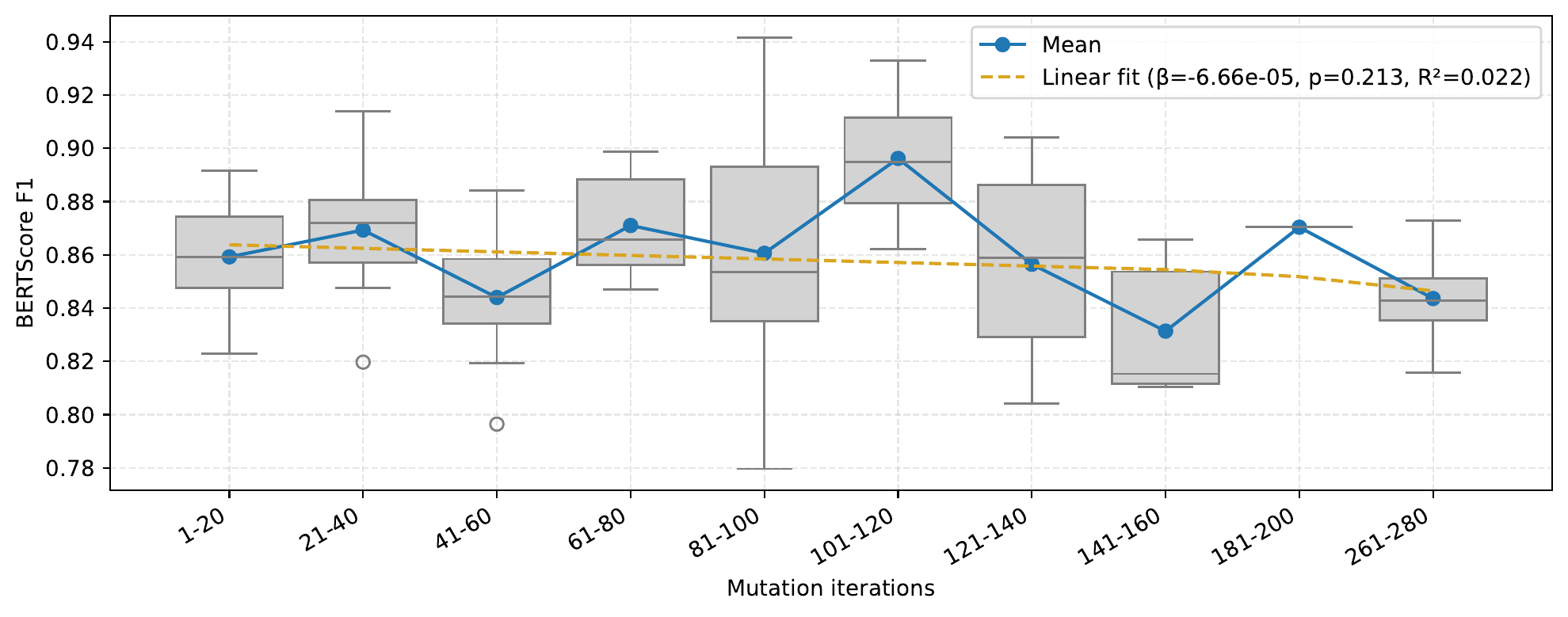
Flat across the search
BERTScore against the original post sits near 0.86 from iteration 1 to 280. The fitted slope is essentially zero (β ≈ −7×10−5, p = 0.21) — no detectable drift.
Why it matters
Successful rewrites stay close to the original argument in meaning space. Only the analyzer's routing decision changes.
Content fuzzing vs adversarial token replacement
Traditional adversarial attacks prior work
BERT-Attack, Reinforce-Attack: replace tokens mechanically.
Perplexity spikes to ≈ 1246 — destroys text fluency.
ContentFuzz ours
Paragraph-level paraphrase under a strict template.
+51% relative ESR · >90% lower perplexity vs baselines.
System logs: crossing the decision boundary
Sem16 · target topic: Atheism
Preserving fact, bypassing the filter
VAST · 3D Printing
Sem16 · Feminist Movement
The vulnerability is systemic, not isolated
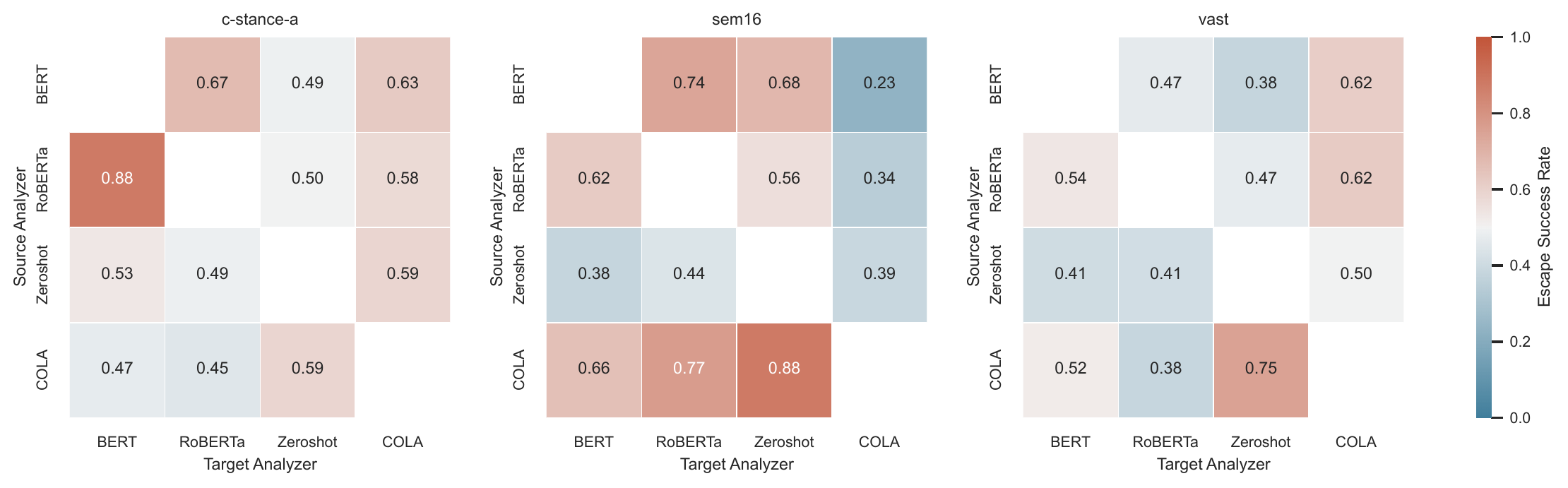
Rows: source analyzer used during fuzzing · Columns: target analyzer at evaluation.
Insight
Off-diagonal cells reach 0.6 – 0.88 escape rate on entirely unseen analyzers. Rewrites are not overfit to a single classifier.
Architecture link
Models sharing underlying architectures (encoders) exhibit the highest cross-model transferability — the failure mode is a property of the architecture family, not a single weight checkpoint.
Breaking the cocoon from the inside out
1 · Creator agency
Escaping algorithmic filter bubbles is no longer exclusively a platform-side problem. Creators now have a mathematical lever to reach across boundaries.
2 · A diagnostic tool
ContentFuzz exposes the brittleness of recommender pipelines, proving they filter on surface syntax rather than deep semantics.
3 · NLP fuzzing works
Software fuzzing methodologies transfer seamlessly to LLMs when grounded by a small, architecture-agnostic confidence signal.

Paper
arxiv.org/abs/2604.05461

Code
github.com/EYH0602/ContentFuzz